Keyword [Word-CNN-RNN] [Character-CNN-RNN]
Reed S, Akata Z, Lee H, et al. Learning deep representations of fine-grained visual descriptions[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 49-58.
1. Overview
1.1. Motivation
attribute-based zero shot
- attribute do not provide a natural language interface
- fine-grained recognition requires commensurately more attribute
- natural language provides a flexible and compact way of encoding only the salient visual aspects for distinguishing categories
In this paper, it proposed word or character based methods
- word-CNN-RNN
- character-CNN-RNN
1.2. Related Work
- fine-grained classification
- zero-shot
- image and video caption
2. Methods
2.1. Embedding
2.1.1. Objective

2.1.2. Inference
compatibility

classifier
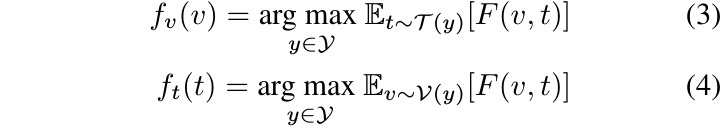
2.1.3. Learning
- since 0-1 loss is discontinue

2.2. Text-based ConvNet

- image width is 1 pixel, channel number is equal to the alphabet size
2.3. Convolutional Recurrent Net (CNN-RNN)

- only CNN lacks a strong temporal dependency along the input text sequence
- low-level temporal features learned by efficiently with fast CNN
- temporal structure can still be exploitd at the more abstract level of mid-level features
- final encoded feature is the average hidden unit activation over the sequence

3. Experiments
3.1. Dataset
- CUB
- Flowers
3.2. Details
- crop
- horizontal flip
- length of words 30. length of character 201
- RMSprop
3.3. Comparison



